创新背景
目前,智能手机和嵌入式平台等边缘设备上已经广泛部署深度学习模型来进行推理。其中,训练仍然主要是在具有 GPU 等高通量加速器的大型云服务器上完成。集中式云训练模型需要将照片和按键等敏感数据从边缘设备传输到云端,从而牺牲了用户隐私并导致了额外的数据移动成本。
因此,为了使用户在不牺牲隐私的情况下个性化他们的模型,联邦学习等基于设备的训练方法不需要将数据整合到云端,也能执行本地训练更新。这些方法已被部署在谷歌 Gboard 键盘上以个性化键盘建议,也被 iPhone手机用来提升自动语音识别。同时,当前基于设备的训练方法不支持训练现代架构和大模型。在边缘设备上训练更大的模型不可行,主要是有限的设备内存无法存储反向传播激活。ResNet-50 的单次训练迭代所需的内存是推理的 200 多倍。

以往工作提出的策略包括集成分页到辅助内存和重新实现,以减少云端训练的内存占用。但是,这些方法会显著增加整体能耗。与集成分页方法相关的数据传输通常需要比重计算数据更多的能量。随着内存预算的缩减,重新实现会以 O(n^2 ) 的速度增加能耗。
重新实现和集成分页是降低大型 SOTA ML 模型内存消耗的两种技术。
在重新实现中,一旦不再需要激活张量就会被删除,最常见的是在前向传播期间。从而释放了宝贵的内存,可用于存储后续层的激活。当再次需要删除的张量时,该方法会根据谱系的规定从其他相关的激活中重新计算。
而集成分页,也称为 offloading,是一种减少内存的补充技术。在集成分页中,不是立即需要的激活张量从主存储器调出到二级存储器,例如闪存或 SD 卡。当再次需要张量时,将其分页。
集成分页的一个主要优点是,根据内存总线的占用情况,可以进行 pipelin 处理,以隐藏延迟。这是因为现代系统具有 DMA(直接内存访问)特性,它可以在计算引擎并行运行时将激活张量从辅助存储移动到主内存。例如,在时间步 T7,可以同时将 L6 调出并计算 L7。但是,重新实现是计算密集型的,不能并行化,这导致运行时间增加。例如,我们必须将时间步 T14 用于重新计算 L3,从而延迟其余反向传播执行。
创新过程
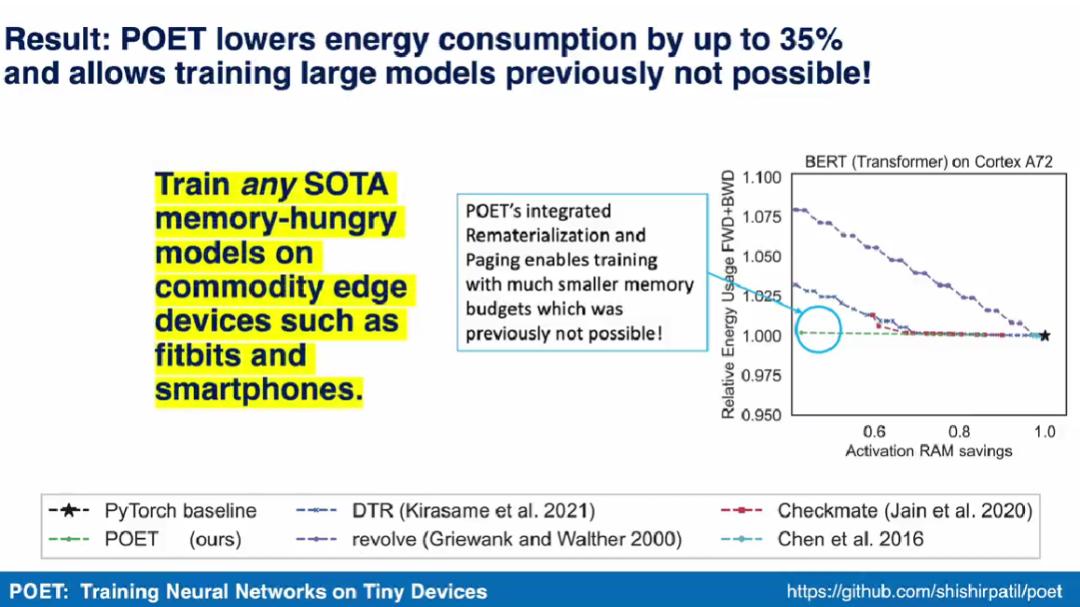
在本研究中,UC 伯克利的几位研究者表明集成分页和重新实现是高度互补的。通过对简单操作重新实现,同时将复杂操作的结果分页到闪存或 SD 卡等辅助存储器上,达到了以最小的能耗扩展有效的内存容量的效果。并且,通过这两种方法的结合,研究者还证明了在移动级边缘设备上训练 BERT 等模型是可能的。通过将边缘训练看作一个优化问题,他们发现了在给定内存预算下实现最小能耗的最优调度。

研究者提出了 POET(Private Optimal Energy Training),这是一种在内存受限边缘设备上对现代神经网络进行能量最优训练的算法,其架构如下图 1 所示。鉴于为反向传播缓存所有激活张量的成本极高,POET 对激活进行优化集成分页和重新实现,因而可以将内存消耗最高减少两倍。他们将边缘训练问题重新表述为整数线性程规划(ILP),发现可以通过求解器在 10 分钟内将其求解到最优。
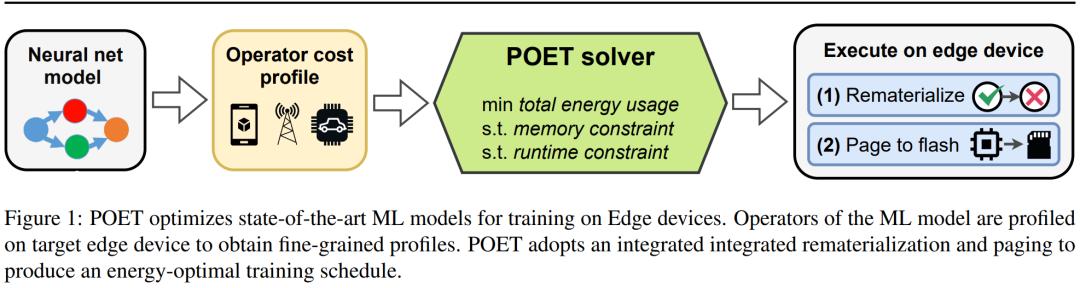
对于部署在真实世界边缘设备上的模型,当边缘设备出现空闲并可以计算周期时就会进行训练,例如谷歌 Gboard 会在手机充电时安排模型更新。因此,POET 也包含了严格的训练限制。给定内存限制和训练 epoch 的数量,POET 生成的解决方案也能满足给定的训练截止期限。
此外,研究者还利用 POET 开发了一个全面的成本模型,并证明它在数学上是保值的(即不做近似),适用于现有的开箱即用架构。
论文作者表示,POET 算法可以在智能手机等商用边缘设备上训练任何需要极大内存的 SOTA 模型。他们也成为了首个展示在智能手机和 ARM Cortex-M 设备上训练 BERT 和 ResNet 等 SOTA 机器学习模型的研究团队。
POET
该研究提出的POET是一种用于深度神经网络的图形级编译器,它重写了大型模型的训练 DAG,以适应边缘设备的内存限制,同时保持高能效。
POET 是硬件感知的,它首先跟踪前向和后向传播的执行以及相关的内存分配请求、运行时间以及每次操作的内存和能源消耗。对于给定的硬件,每个工作负载的这种细粒度分析只发生一次,具有自动化、便宜等特性,并且为 POET 提供了最准确的成本模型。POET 然后生成可以有效求解的混合整数线性规划 (MILP)。
POET 优化器搜索有效的重新实现和集成分页调度,以最大限度地减少受内存限制的端到端能源消耗。然后使用得到的调度生成一个新的 DAG,在边缘设备上执行。
虽然 MILP 是在商用硬件上解决的,但发送到边缘设备的调度表只有几百字节,因此内存效率很高。
对于计算成本低但内存密集型的操作,重新实现是最有效的。然而,集成分页最适合于计算密集型操作,在这种操作中,重新实现将导致大量的能量开销。POET 在一个集成搜索空间中共同考虑重新实现和集成分页。
本文方法可扩展到复杂、现实的架构中,POET 优化器算法如下。

该研究在优化问题中引入了一个新的目标函数,以最小化计算、page-in 和 page-out 的综合能耗,集成分页和重新实现能耗结合的新目标函数为:
其中Φ_compute、Φ_pagein 和Φ_pageout 分别表示每个节点在计算、page-in 和 page-out 时所消耗的能量。
POET 根据图的哪些节点 (k) 进行了重新实现,以及在每个时间步长 (t) 将哪些节点 page-in
或 page-out
来输出 DAG 调度。

创新价值
UC 伯克利的几位研究者提出了一种用于深度神经网络的图形级编译器——PORT,它重写了大型模型的训练 DAG以适应边缘设备的内存限制,同时保持高能效,通过重新实现和集成分页,达到了以最小的能耗扩展有效的内存容量的效果。
智能推荐
人工智能创新思维 | 新型人工智能系统利用光进行联想学习
2022-08-09牛津大学材料系的研究人员与埃克塞特大学和明斯特大学的同事合作开发了一种片上光学处理器,能够以比在电子处理器上运行的传统机器学习算法快1000倍的速度检测数据集的相似性。
涉及学科涉及领域研究方向人工智能+古文字学 | 人工智能帮助研究古文字文本
2022-07-28将人工智能运用于古文字学领域,帮助重建古老的文字文本,探索人类的历史文明。
涉及学科涉及领域研究方向机器人工程创新思维 | 融合动作、视觉和语言预制模型的导航方法使机器人执行自然语言指令
2022-07-26这项研究首次将预训练的视觉和语言模型与目标条件控制器相结合的想法实例化,以在目标环境中不进行任何微调的情况下得出可操作的指令路径。值得注意的是,这三个模型都是在大规模数据集上训练的,具有自监督的目标函数,并且在没有微调的情况下现成使用,训练 LM Nav 也不需要对机器人导航数据进行人工注释。
涉及学科涉及领域研究方向机器学习创新思维 | 新型硬件“智能收发器”可利用硅光子学加速运算
2022-10-25研究人员开发了一种新方法使用光学器件来加速智能扬声器和其他低功耗连接设备上的机器学习计算。
涉及学科涉及领域研究方向