创新背景
自监督学习长久以来都是视觉领域努力追求的目标,它能够帮助我们利用大量的无标注数据,并且推动了很多下游任务的进步。
为了有效地以自监督的方式训练网络,研究者们提出了各式各样的 “代理任务”(pretext task)来生成监督信号,其中最为典型的有两类框架:Instance Discrimination(ID)与 Masked Image Modeling(MIM)。
ID 方法希望拉近相同图像的不同增强视图,同时避免特征坍塌(包括 MoCo、BYOL、Barlow Twins 等方法)。这种方法学习到的特征往往具有很强的线性可分性,所以 ID 方法在线性分类任务上表现出色,但是近期的一些研究表明它在下游的检测任务上并不优于监督学习。另一方面,MIM 方法通过一张遮盖图像来重建原始图像(包括 BEiT、MAE 等方法),它通常在检测任务上表现优异,但是不能做好线性分类任务,而且在少样本场景下表现一般。

创新过程
为了现有的矛盾,来自清华和商汤的研究者们提出:这种差异是因为两种方法各自忽略了特征所需要的语义对齐和空间分辨能力。具体来说:
语义对齐能力要求语义相似的图像能被映射到邻近的特征表示,这可以通过对比相同图像的不同增强视图来达到;
空间分辨能力要求特征能够建模图像内部的空间结构,而通过遮盖图像去预测密集特征表示能够帮助达成这点,因为这种做法建模了图像内部的条件分布。
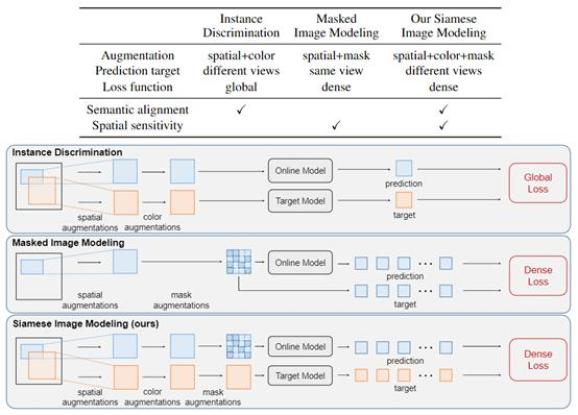
基于这些思考,研究者提出了 Siamese Image Modeling(SIM),该方法通过一张遮盖的增强视图来预测相同图像的另一张增强视图的密集特征表示。
为了达到这个目标,SIM 采用了孪生网络结构,该结构包含 online 和 target 两个分支。Online 分支首先将第一张遮盖视图映射到特征空间,然后基于第一张图的特征和第一、二张图的相对位置坐标来预测第二张图的特征;Target 分支则负责将第二张图映射到特征空间来获得目标特征。
通过这种方式,SIM 能够分别在线性分类任务上和 ID 方法持平,以及在检测任务上和 MIM 方法持平,研究者进一步发现即便没有全局的损失函数,SIM 也能给出很好的线性分类表现。
方法
数据增强
数据增强策略对于特征的学习有着非常重要的作用:ID 方法已经揭示了更强的空间和颜色增强对于提升线性分类效果显著;MIM 方法则采用了遮挡增强来帮助模型学习图像的局部结构。因此,SIM 保留了 ID 方法中的强数据增强策略,同时对输入给 online 分支的视图采用遮挡增强策略。
预测目标
SIM 被设计成去预测相同图像的不同增强视图的密集特征,这里将介绍预测和目标分别是如何计算的。
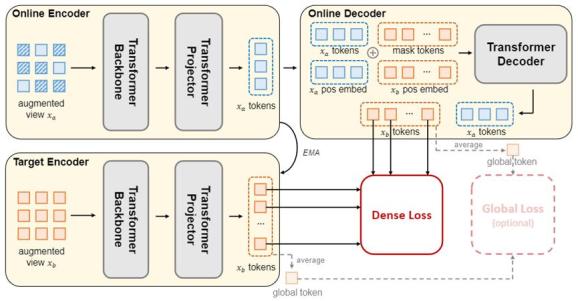
Online 分支负责做出预测。它首先将第一张遮挡视图 x_a 映射成特征 y_a∈R^(N_v×D),之后利用解码器 g (⋅) 基于特征 y_a,掩码词符 m 和他们的位置编码来做出预测
其中,p_a 是第一张视图 x_a 的位置编码,p_b^((u,v) ) 对应第二张视图 x_b 在 (u,v) 处的图块的位置编码,它们会在下文介绍。
Target 分支负责给出目标。它的编码器是 Online 分支编码器的滑动平均,并且接收第二张视图的所有图块并编码为目标特征 z_b∈R^(N×D)。
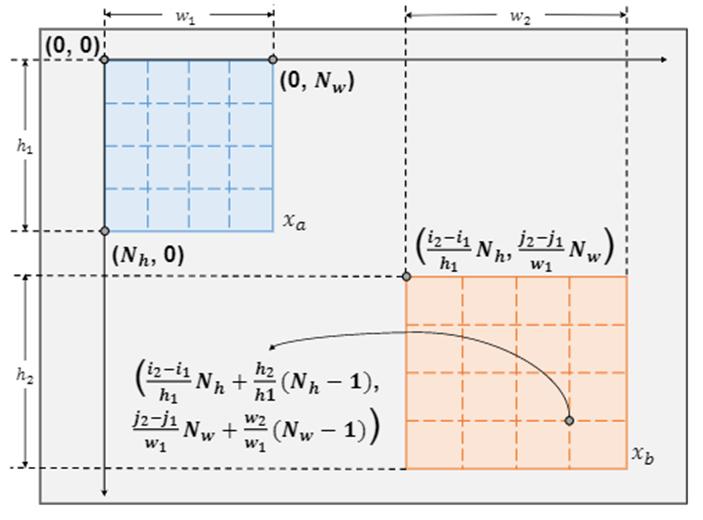
最后介绍解码器所需的位置编码是如何计算的。所有的图块都是以第一张视图 x_a 的左上角作为原点来计算的。具体来说,假设两张视图在原图中的位置信息分别为 (i_1,j_1,h_1,w_1) 和 (i_2,j_2,h_2,w_2 )(分别代表左上角横纵坐标与高度宽度),第一张视图的相对位置为:
第二张视图的相对位置为:
对于第二张图,尺度变化也被进一步加入位置信息中:
最后,这些信息输入到 sincos 位置编码函数中得到如下位置编码:
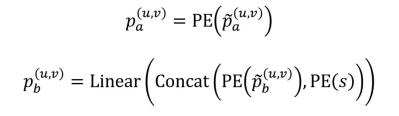
损失函数
SIM 采用 UniGrad 作为损失函数:
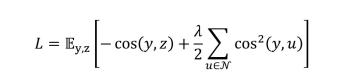
UniGrad 被采用主要出于两个原因:(1)这种对比函数是 ID 方法的统一形式;(2)它对内存更加友好:注意到通常使用的 InfoNCE 损失函数需要 O (|N|) 的内存来计算相似度,这对于有大量负样本的密集层次损失函数是不现实的;而通过先计算负样本之间的相关矩阵,UniGrad 只需要 O (D^2) 的内存消耗。
SIM 尝试将 UniGrad 施加在全局层次和密集层次,全局损失函数用全局平均的特征作为整张图的特征:
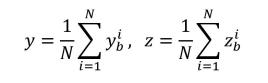
而密集损失函数将每个图块作为单独的样本,并且为了减少与全局损失函数的冲突,每个图块的特征减去了全局平均特征:
最后的总体的损失函数为:
研究者发现在短轮数下,(α_1=1,α_2=4) 给出最好的性能取舍。有趣的是,当训练轮数足够长时,只使用密集损失函数 (α_1=0,α_2=1) 也能给出很好的线性分类性能。
实验
主要结果
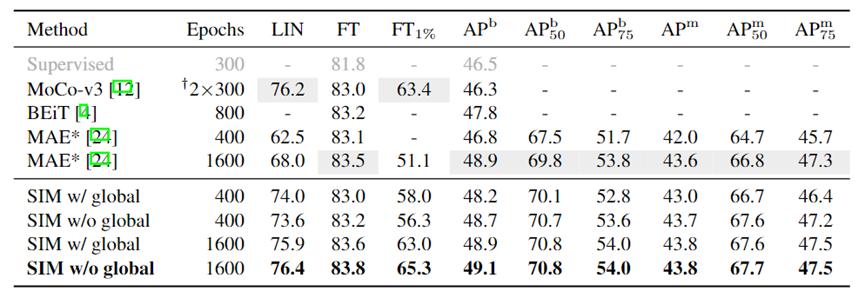
研究者在多种评估指标下对比了 SIM 和其它方法的性能,包括线性分类、ImageNet 全数据微调、ImageNet 1% 数据微调、COCO 上的物体检测与实例分割。
线性分类方面,SIM 可以做到和 MoCo-v3 相当的水平,同时大幅超过 MAE(400ep 大约 11 个点,1600ep 大约 8 个点);同时,即便不使用全局损失函数,SIM 也能给出不错的线性分类结果;
检测与分割任务上,SIM 超过了 MoCo-v3 大约 2 个点,也能在使用更短轮数的条件下达到与 MAE 相当的水平(400ep v.s. 1600ep);
微调任务上,SIM 在全数据微调时可以达到和之前方法相当的水平,而当只有 1% 数据可用时,SIM 能够超过 MoCo-v3 2 个点,MAE 14 个点。
消融实验
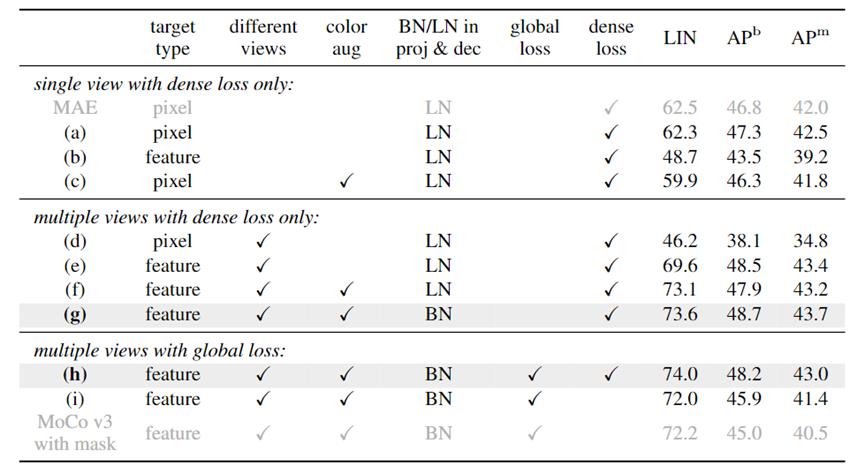
预测像素还是特征。表中(ab)和(de)说明,在使用相同视图作为输入和目标时,预测像素性能更好;而使用不同视图时,预测特征性能更好;
不同视图。表中(ae)和(cf)说明,使用不同视图能够提升线性分类大概 7-13 个点;
颜色增强。表中(ac)和(ef)说明,对于不同视图,颜色增强可以提升线性分类 3.5 个点,不过对于相同视图则没有这种提升效果。研究者猜测相同视图会将预测目标所采用的颜色增强泄露给模型,从而破坏了对颜色不变性的建模;
对 projector 与 decoder 使用 BN 还是 LN。研究者尝试将 projector 和 decoder 中的归一化层从 LN 换成 BN,表中(fg)说明这种替换对线性分类与检测任务都有一些提升;
全局损失函数。表中(gh)说明,全局损失函数有利于线性分类性能的提升,但是并不是必要的;
密集损失函数。表中(hi)说明密集损失函数能够在物体检测任务上提升 2.3 个点,在实例分割任务上提升 1.6 个点,这说明密集损失函数对下游密集预测任务是有帮助的。
智能推荐
计算机图像处理创新思维 | 创新“可组合扩散”法可使用多个模型创建更复杂的图像
2022-10-10研究人员开发了一种新方法,该方法使用多个模型来创建更复杂的图像,并具有更好的理解力。
涉及学科涉及领域研究方向