创新背景
在计算机视觉任务中,有一项基础任务是了解真实世界的 3D 环境,我们可以将输入介质如 RGB、RGB-D 视频或单个图像等进行 3D 重建来了解周围物体。这种使用有源相机(active cameras)的方法表明:利用强视觉信号可以有效的捕获物体几何结构。现在我们考虑这样一种情况(一种非常规的被动 3D 场景感知视图):在缺乏视觉信息的情况下,我们想要查看人体姿态数据,并询问「我们可以仅从人体姿态轨迹信息中了解 3D 环境的哪些信息?」这些研究为探索可穿戴设备开辟了新的可能性。
有研究表明 3D 环境中的人类运动经常与环境中的对象进行被动或主动交互,这种交互以及人类的运动轨迹往往能够为机器提供该场景中的物品摆放的许多信息。例如,人在房间里走动表明有空的地板空间,人的坐姿动作表明此处可能有椅子或沙发,单臂伸出表明拿起 / 放下某些物体。
那么我们能否仅从人类轨迹信息中推断现实环境中的对象结构?
创新过程
来自慕尼黑工业大学、香港中文大学(深圳)的研究者提出了一种新的场景模拟的方法——P2R-Net :仅仅依靠对3D人体姿态的观察,就能估计与人交互的物体在场景中的摆放位置,该模型的特征是其类别和定向 3D 边框。结果表明,P2R-Net 在 PROX 数据集和 VirtualHome 平台上始终优于基线。该研究入选了 ECCV 2022。

根据人的行走轨迹、身体动作等,就能建模出房间内的物体摆设。例如下面动图中,当人走到右边有坐下的动作时,表明与人交互的场景中有沙发或椅子这个物体。
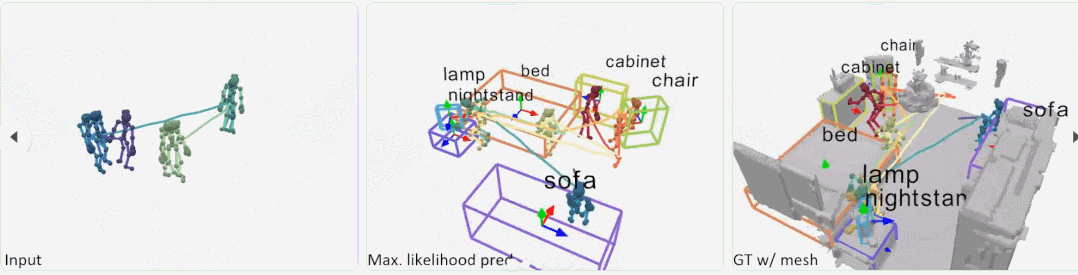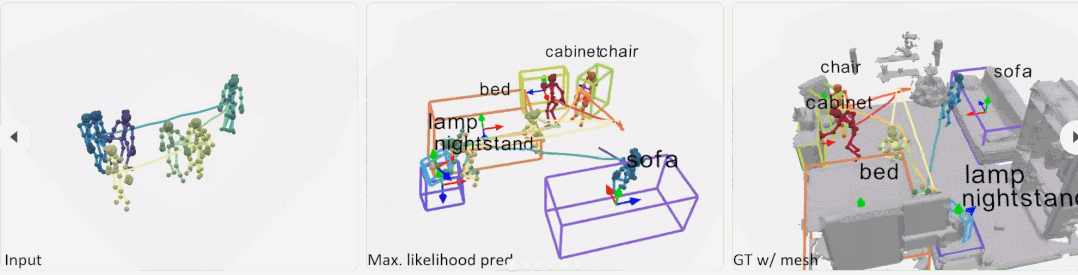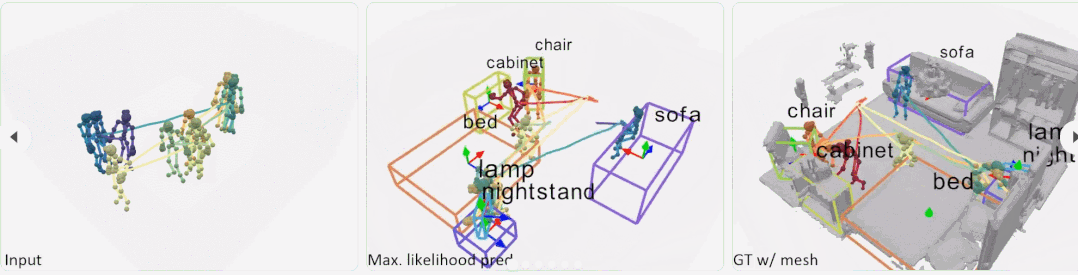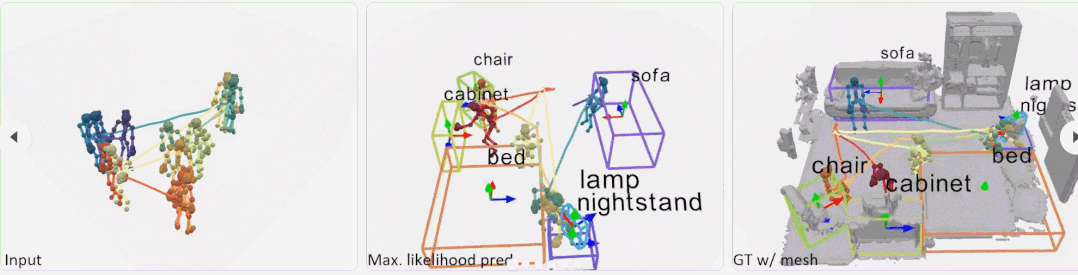
操作方法
研究者首先使用位置编码器从人体姿态序列中提取有意义的特征,以将每帧分解为相对位置编码和与位置无关的姿态,以及使用姿态编码器来学习连续帧中每个姿态的局部时空特征。然后,利用这些特征为每个姿态投票选出一个潜在的交互对象。从这些投票中,文中方法学习了一个概率混合解码器,为每个对象提出框建议,描述对象、类标签和框参数的可能模式。
给定具有 N 帧和 J 个关节的姿态轨迹,位置编码器将每个骨架帧解耦为相对位置编码(从其根关节作为臀部质心)和与位置无关的姿态。在组合它们之后,姿态编码器从每个骨架的身体关节(空间编码)及其在连续帧中的变化(时间编码)学习局部姿态特征。然后,作为种子的根关节用于投票选出每个姿态可能与之交互的附近对象的中心。概率混合网络学习可能的对象框分布,从中可以对对象类别标签和定向 3D 框进行采样。
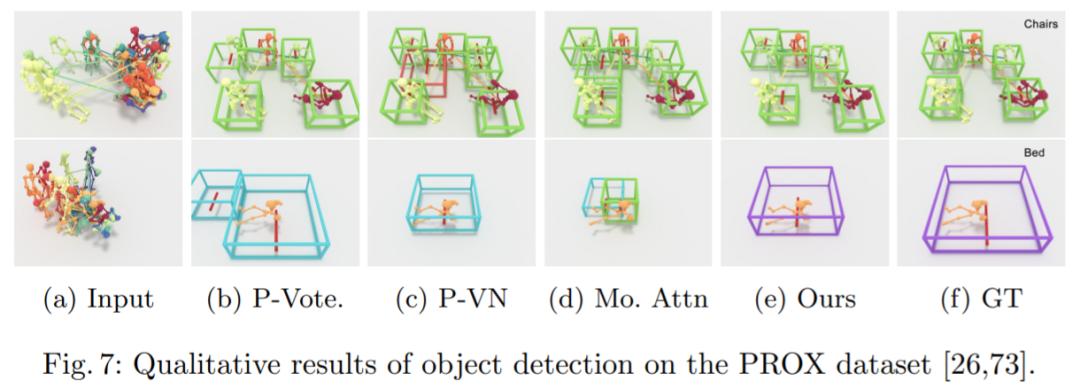
为了实现大规模训练,该研究引入带有 VirtualHome 平台的大规模数据集,以从人体运动中学习对象配置。在 VirtualHome 和真实数据集 PROX 上的实验证明,P2R-Net 与基线方法相比表现出较强的优越性。
创新关键点
该研究提出了一种新的方法——P2R-Net,能够通过记录人的行动轨迹和身体动作构建出房间内可能存在的物品摆设位置。该研究将为扫地机器人等智能设备的提供新思路。
智能推荐
开发“自传式记忆”系统加强人机互动
2022-08-18通过开发自传式记忆系统,使机器人能够存储传播人类知识,增强人机互动联系,方便空间站中的宇航员工作。
涉及学科涉及领域研究方向机器人+生物工程 | 创新开发具有活皮肤组织的机器人手指
2022-11-07机器人手指具有活细胞和支持在其上生长的有机材料,可实现理想的形状和强度。
涉及学科涉及领域研究方向